그룹쿼리(GROUP QUERY)
그룹 쿼리는 데이터를 특정 컬럼을 기준으로 그룹화하고, 각 그룹에 대한 집계 함수를 사용하여 요약 정보를 생성한다.
집계함수
집계함수란 대상 데이터를 특정 그룹으로 묶은 다음 이 그룹에 대해 총합, 평균, 최댓값, 최솟값 등을 구하는 함수를 말한다.
① COUNT (expr)
📍COUNT는 쿼리 결과 건수, 즉 전체 행의 개수를 반환하는 집계 함수다. 테이블 전체는 물론 WHERE 조건으로 걸러진 행의 개수를 반환한다.
COUNT(*)=107
📍COUNT 함수는 매개변수로 들어오는 expr이 NULL이 아닌 건에 대해서만 행의 개수를 반환한다.
COUNT(DEPARTMENT_ID)=>106
COUNT(DISTINCT DEPARTMENT_ID)=>11
DISTINT DEPARTMENT_ID=>12행 출력(NULL포함)
② SUM(expr)
SUM은 expr의 전체 합계를 반환하는 함수로 매개변수 expr에는 숫자형만 올 수 있다.
SUM(SALARY)=>691416
③ AVG(expr)
AVG는 매개변수 형태나 쓰임새는 COUNT, SUM과 동일하며 평균값을 반환한다.
AVG는 NULL값을 제외하고 계산하고 COUNT
SELECT ROUND (AVG(SALARY),3) 월급평균, --6461.832
ROUND(SUM(SALARY)/COUNT (EMPLOYEE_ID),3) 월급평균 --6343.266
FROM EMPLOYEESROUND(691416/107,3) => 6461.832
ROUND(691416/109,3) => 6343.266 ∵null값을 포함해서 행의 개수(=EMPLOYEE_ID의 개수)가 109개가 된다.
④ MIN(expr), MAX(expr)
MIN과 MAX는 각각 최솟값과 최댓값을 반환한다.
⑤ VARIANCE(expr), STDDEV(expr)
VARIANCE는 분산을, STDDEV는 표준편차를 구해 반환한다.
GROUP BY 절과 HAVING 절
특정 그룹으로 묶어 데이터를 집계할 수 있다.
①GROUP BY
GROUP BY 절에 명시해서 사용하며 GROUP BY 구문은 WHERE와 ORDER BY절 사이에 위치한다. SELECT문에 집계함수가 있을때 일반값을 출력하기 위해선 GROUP BY절이 필요하다.
SELECT DEPARTMENT_ID 부서번호,
COUNT(*) 인원수,
SUM(SALARY) 월급합,
ROUND(AVG(SALARY),3) 월급평균
FROM EMPLOYEES
WHERE DEPARTMENT_ID IN (60,50,90)
;위와 같이 쿼리를 작성하면
| 부서번호 | 인원수 | 월급합 | 월급평균 |
| 60 | COUNT(*) | SUM(SALARY) | ROUND(AVG(SALARY),3) |
| 50 | |||
| 90 |
이런 식으로 되는데 SQL에서는 열과 행이 모두 채워져야 하기때문에 아래와 같이 WHERE문 다음에 GROUP BY문을 위치시켜 부서별 60, 50, 90 의 인원수, 월급합, 월급평균을출력할 수 있다.
GROUP BY DEPARTMENT_ID -- ~별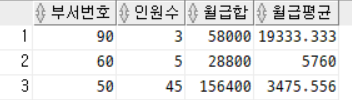
💡GROUP BY는 alias(별칭)이 사용불가능하다.(ORDER BY에서는 사용가능)
② HAVING
HAVING 문은 SQL에서 GROUP BY로 그룹화된 결과에 대해 조건을 설정하는 데 사용된다. HAVING은 집계 함수와 함께 사용하여 그룹의 결과를 필터링할 수 있다. 즉, HAVING은 그룹화된 데이터의 조건을 지정하는 반면, WHERE는 그룹화 이전의 데이터를 필터링한다.
부서별 사원수가 5명 이상인 부서번호를 구하는 쿼리를 다음과 같이 작성할 수 있다.
SELECT DEPARTMENT_ID,
COUNT(EMPLOYEE_ID)
FROM EMPLOYEES
GROUP BY DEPARTMENT_ID
HAVING COUNT(DEPARTMENT_ID)>=5
;
ROLLUP 절과 CUBE 절
ROLLUP과 CUBE는 GROUP BY절에서 사용되어 그룹별 소계를 추가로 보여 주는 역할을 한다.
①ROLLUP(expr1, expr2, …)
ROLLUP은 집계 함수와 함께 사용되어 다차원 집계 결과를 생성하는 기능이다. 주로 GROUP BY 절과 함께 사용되며, 데이터의 계층적 요약을 제공한다.
SELECT DEPARTMENT_ID, JOB_ID, COUNT(*)
FROM EMPLOYEES
GROUP BY ROLLUP(DEPARTMENT_ID, JOB_ID)
;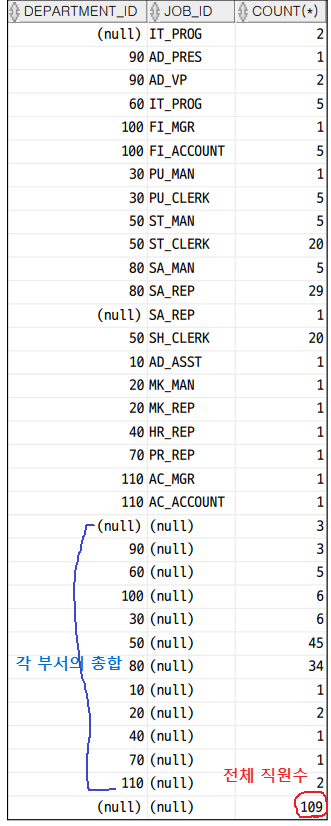
위 쿼리는 각 부서와 직급에 대한 직원 수를 계산하고, 각 부서의 총합 및 전체 직원 수도 포함된 결과를 출력한다.
ROLLUP을 사용하면 데이터 분석 시 더 유용한 결과를 얻을 수 있다.
② CUBE
CUBE는 다음과 같이 지정된 컬럼의 모든 가능한 조합에 대한 집계를 생성한다.
SELECT DEPARTMENT_ID, JOB_ID, COUNT(*)
FROM EMPLOYEES
GROUP BY CUBE(DEPARTMENT_ID, JOB_ID)
ORDER BY DEPARTMENT_ID, JOB_ID ASC --오름차순 정렬
;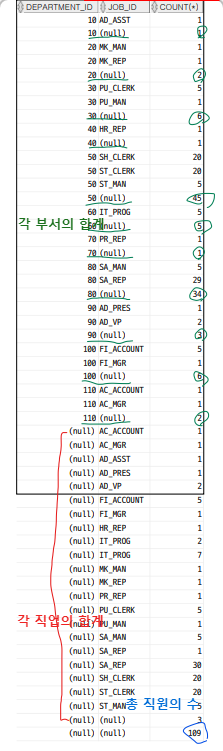
이 쿼리는 각 부서와 직급의 직원 수를 계산하고, 각 부서의 총합, 각 직급의 총합, 그리고 전체 직원 수도 포함된 결과를 출력한다.
서브쿼리(SUB QUERY)
SQL에서 다른 쿼리의 내부에 포함된 쿼리. 서브쿼리는 주 쿼리의 조건을 결정하거나 데이터를 필터링하는 데 사용된다. 서브쿼리는 일반적으로 괄호로 감싸져 있으며, SELECT, INSERT, UPDATE, DELETE 문 등 다양한 SQL 문에서 사용할 수 있다.
예제:최대 월급자의 명단과 최소 월급자의 명단을 출력하시오.
SELECT EMPLOYEE_ID 사번,
FIRST_NAME||' '||LAST_NAME 이름,
SALARY 월급
FROM EMPLOYEES
WHERE SALARY=(SELECT MAX(SALARY) --최대 월급자
FROM EMPLOYEES)
OR SALARY=(SELECT MIN(SALARY) --최소 월급자
FROM EMPLOYEES)
;OR문 대신 IN을 사용해서 아래와 같이 작성할 수도 있다.
SELECT EMPLOYEE_ID 사번,
FIRST_NAME||' '||LAST_NAME 이름,
SALARY 월급
FROM EMPLOYEES
WHERE SALARY IN ((SELECT MAX(SALARY)
FROM EMPLOYEES),
(SELECT MIN(SALARY)
FROM EMPLOYEES)
)
;⚠️오류일때의 경우
WHERE SALARY IN (SELECT MAX(SALARY), MIN(SALARY)
FROM EMPLOYEES)
);
=> 메인쿼리의 SALARY는 한칸이고 서브쿼리는 두칸
∴ 비교안됨 ORA-00913:값의 수가 너무 많습니다.
📍아래와 같이 다른 테이블를 서브쿼리로 불러올 수도 있다.
'IT'부서의 평균월급보다 많은 월급을 받는 사람명단
SELECT EMPLOYEE_ID 사번,
FIRST_NAME||' '||LAST_NAME 이름,
SALARY 월급
FROM EMPLOYEES
WHERE SALARY>=(SELECT AVG(SALARY)
FROM EMPLOYEES
WHERE DEPARTMENT_ID=(SELECT DEPARTMENT_ID
FROM DEPARTMENTS
WHERE UPPER(DEPARTMENT_NAME)='IT'
)
)
;📍서브쿼리는 데이터베이스에서 보다 복잡한 질의를 수행할 때 매우 유용하며, 다양한 상황에서 활용될 수 있다.
'SQL' 카테고리의 다른 글
| [SQL]WINDOW FUNCTION(윈도우 함수),분석함수(Analytic Function) (0) | 2024.09.04 |
|---|---|
| [sql] 계층형 쿼리(Hierarchical Query) (0) | 2024.09.04 |
| [SQL] 집합 연산자(UNION, UNION ALL, INTERSECT, MINUS),INLINE VIEW (0) | 2024.09.03 |
| [sql]JOIN, ANSI JOIN (0) | 2024.09.02 |
| [SQL] 함수 (1) | 2024.08.30 |